Ordinal regression can be understood as multi class classification over an ordered label set. For example, consider a hiring scenario, where given a job applicant’s features, such as their prior experience or education, we want to predict a label in {bad, okay, good, excellent}. Perhaps surprisingly, fairness for ordinal regression has not been studied to date. The order information not only entails that different kinds of misclassifications should be weighted differently, but also has certain implications when we try to be fair in such a prediction task. For example, an applicant that should be scored as ‘okay’ would feel treated unfairly if misclassified as bad, but probably not if they were misclassified as good. Or it might be acceptable to misclassify all excellent applicants from a minority group as good as long as all other excellent applicants from other (majority) groups are misclassified in the same way.
In this project[ ] we focus on two group fairness notions adapted from the literature on fair ranking and present a strategy to learn a predictor that is accurate and approximately fair according to either one of these notions. Typically a trade-off exists between accuracy and fairness, and our strategy allows us to control this trade-off via a parameter. In extensive experiments, we show that for different choices of the parameter we typically obtain predictors with different accuracy-vs-fairness performance and our strategy allows us to explore the trade-off. Often, our strategy compares favorably to state-of-the-art methods for ordinal regression that do not take fairness into account in that it yields predictors that are only slightly less accurate, but significantly more fair than the predictors produced by those methods.
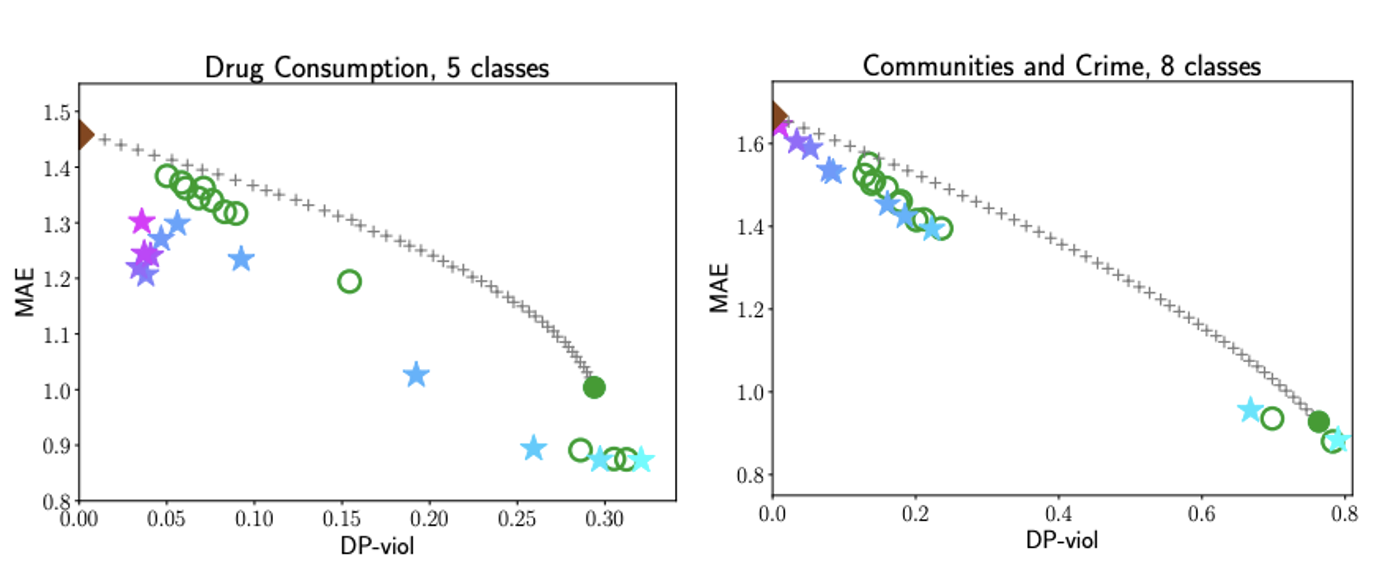
One of measures of fairness that we consider here is pairwise demographic parity (Pairwise DP). Pairwise DP is the requirement that it is as likely for a point sampled from one protected group to be preferred over a point sampled from a second group as it is for the converse to happen (e.g., a female applicant being considered better than a male applicant happens just as likely as a male applicant being considered better than a female one). The figure above describes an example of our methods performance compared to an state-of-the-art method on two publicly available datasets: “Drug Consumption” and the “Communities and Crime”. The performance is measured with respect to the accuracy of prediction measured by mean absolute error (MAE) and violation of pairwise DP (DP-viol). Stars indicate performance of our algorithm for different parameter values. Circle indicates the performance of a classical technique for ordinal regression known as the proportional odds model and + line is the baseline.